
HTTP-Protokoll
Für die Quelle finden Sie selbst heraus, was das allgemeine Protokoll ist. Protocol - ist ein Satz von Regeln und Schlüsselfiguren, für die Kommunikation zwischen einem Gerät vorgesehen. Es ist notwendig, dass auf Computer oder deren Elemente die Buddy-Buddy klar verstehen können.
Minutes - Kommunikation Computer im Netzwerk zu sprechen.
In der Tat erlaubt nur ein Satz von Befehlen, das Protokoll zu nennen, aber das Konzept des Protokolls gilt nur in der Praxis so genannte Netzwerkprotokolle - Sprachkommunikation Computern im Netzwerk. Jedes Protokoll hat einen bestimmten Zweck und durch spezialisierte Software unterstützt.
URL, IP- und DNS-Adressen, Domains
So URL (Uniform Resource Locator) ist der vollständige Pfad des Dokuments. URL ist die Adresse, an der auf jeden Fall erlaubt das Dokument finden (Datei) im Internet. Diese Linie, die Sie im Feld "e" vyshego Browser eingeben essen auch die URL des Dokuments.
URL kann genug etwas schwierig, da sotoyat aus verschiedenen Teilen besitzen. Betrachten wir zuerst eine einfache URL:
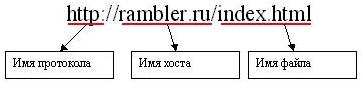
Diese URL hat drei Bestandteile: der Hostname, wo das Dokument, wird der Name des Protokolls verwendet werden, um das Dokument, wie der eigentliche Name der Handlung (die Dateinamen und der Erweiterung) zu übertragen. Die Basis (und die einzige Pflichtanteil für HTTP-Protokoll) Adresse - einen Hostnamen. Er identifiziert die Maschine , auf der die Handlung (in einzelnen Computern Host - Namen Netzwerk). Jeder Computer in dem Netzwerk ist der Host hat auch eine einzigartige (zum Netzwerk) Namen. In der Probe rambler.ru den Computernamen , auf dem wir ein Dokument zu finden möchten.
Hostnamen können redundante Weise definiert werden: durch die Verwendung von DNS und IP-Adressen. Eine IP-Adresse besteht aus vier Zahlen, die durch Punkte getrennt sind. Jede Menge kann von 0 bis 255. Beispiel 192.168.2.1 im Bereich.
In der Praxis zu erinnern, aber unbequem, die IP-Adresse als die Anzahl der schwer zu bedienen. So war vvedna Domain Name System (Domain Name System - DNS), wobei jede IP-Adresse in einer Beziehung oder einen Namen von Buchstaben oder Zahlen aus platziert wird. Zum Beispiel in dem obigen Beispiel DNS - Name war rambler.ru, wie es um die IP - Adresse 217.73.192.109 entspricht.
Es sollte beachtet werden, dass verschiedene IP-Adressen prkticheski entsprechen immer verschiedene DNS-Namen, aber verschiedenen DNS-Namen können die gleiche IP-Adresse antworten. Zum Beispiel, wie eine andere DNS - Namen, und www.rambler.ru rambler.ru haben ein gut , dass bla bla IP - Adresse. Die URL-Adressen sind erlaubt als DNS-Namen zu verwenden, und IP-Adressen. So sind die beiden Adressen als URL http://rambler.ru/index.html http://217.73.192.109/index.html äquivalent. Einige IP - Adresszuweisung Methoden werden hier beschrieben http://www.xakep.ru/post/11980/default.htm .
Wir stellen ferner fest, dass im Prinzip der Host nicht den Domain-Namen zu besitzen hat. Das heißt, einige Hosts Zugriff nur durch IP - Adresse erlaubt sind.
Sie haben wahrscheinlich bemerkt schon die Sorge, dass jeder DNS-Namen durch Punkte getrennt sind aus mehreren Wörtern besteht. Jeder Name Domain bedeutet , allein zu dem der Host. Die gesamte DNS-System ist in einer hierarchischen Art und Weise gebaut. Alle Domänen 1 (com, org, ru, etc.) in der Stammdomäne der Ebene 0 enthalten (die in der Regel nicht geschrieben wird, weil der DNS ist die Standardeinstellung). weitere Level-Domains (wie rambler, Post oder kiew) kommen in Domänen der obersten Ebene und etc. Die Domänen in den DNS werden von rechts nach links geschrieben, in der täglichen Zunahme der Ebene.
Beachten Sie zwei wichtige Funktionen: 1. Die Domain lediglich eine Verwaltungseinheit ist auch kein Host ist. 2. IP-Nummern hängt nicht von der Domäne, in der der Wirt.
So ist die Domain-System wurde von geografischen oder Zielattribut nur für die Klassifizierung von Websites eingeführt wurde, und besitzen keine Beziehung zu dem physischen Gerät an das Internet.
In privdennom die Beispiel - URL , die wir explizit den Namen der Tat gefragt sind wir in der index.html interessiert, aber es ist ein Dokument , auf jeder Website standardmäßig geöffnet werden. Er hält die Position als Namen index.html oder default.html auch im Stammverzeichnis der Website befindet. Wenn wir die URL-Adresse der Website eingeben nicht angeben, wie wir mit dem Dateinamen wollen, wird der Server automatisch zu uns öffnen einen Akt standardmäßig angenommen. So adressieren http://crackchat.h1.ru Äquivalent bei http://crackchat.h1.ru/index.html. So wie es ein bla bla-Datei wird standardmäßig geöffnet ist, gibt es auch die Ordner Posteingang standardmäßig aktiviert. In den meisten Servern hat der Standardordner für HTTP - Dokumenten den Namen WWW.
Nach der DNS in der URL muss der Name des Gesetzes sein, auf die wir verweisen. Dies setzt voraus, dass die Datei im Stammordner ist. Wenn bla bla tut es nicht, dann können wir den vollständigen Pfad zum Zertifikat angeben, die Auflistung der Unterordner durch den Schrägstrich:
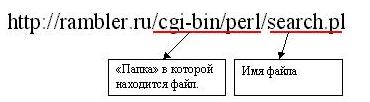
In diesem Beispiel verweisen wir auf eine Datei im cgi-bin / perl / Verzeichnis. Dieser Pfad ist relativ zum Stammordner. Zum Beispiel, wenn der Pfad zur Wurzel von f: / www, dann in unserem Beispiel wenden wir uns in die Datei f: /www/cgi-bin/perl/search.pl. Zugleich beachten Sie stolz die folgenden: wie die meisten der Web-Server auf dem UNIX-artigen Systemen gebaut wird, dann, wenn Sie den Pfad zur Datei spezifizieren, welches Sie unter Berücksichtigung der Differenz zwischen Klein- und Großbuchstaben zu nehmen. Wenn wir also in die Datei von URL verweisen http://rambler.ru/CGI-BIN/perl/Search.pl, würde der Server eine solche Datei nicht gefunden. Der Unterschied ist auch beeindruckend kleinen Buchstaben in einer Datei nur Route kommt, DNS ist Groß- und Kleinschreibung (das rambler.ru Adresse als RAMBLER.RU Äquivalent essen).
Wie bereits erwähnt, entspricht DNS streng opredelnie IP-Adresse, aber es bedeutet nicht, dass der DNS-Name mit dem Host entspricht, auf die wir verweisen. Oft ist der Gastgeber selbst hält allein in sich selbst eine bodenlose Domains Ebenen. Zum Beispiel h1.ru Website ist ein Host in einer anderen Domäne Ebene, aber er enthält die Third-Level - Domains wie crackchat.h1.ru oder crosswords.h1.ru. Daher gehören die beiden zu einem einzigen Host-Site und sind natürlich die gleiche IP-Adresse! Physikalisch gesehen in diesem Fall sehen die dritte Level - Domains wie Ordner auf dem Host - Festplatte h1.ru auch implementiert werden , zugegriffen könnte wie: h1.ru/crackchat/ auch h1.ru/crosswords/~~V. Zugangsmittel (durch den Bereich der 3. Ebene oder durch einen Plattenpfad) wird durch den Servereinstellungen festgelegt.
Stammdomäne wird als ähnlich zu sein, und daher ist die Mehrheit der URL - Adressen werden in zwei Formate , um anzuzeigen , erlaubt: sowohl die www - Domäne (zB www.crackchat.h1.ru) sowie ohne (crackchat.h1.ru) - in diesem Fall der Server weiterhin automatisch verweist Sie auf den Ordner www, da sie standardmäßig angenommen wird.
Protokolle, Ports, CGI-Protokoll
Wie wir gesehen haben, besteht URL-Adresse aus drei Grundelementen: DNS-Namen, Dateipfad, und der Name des Protokolls. Wenn das erste Paar Element die Position des Dokuments bestimmen kann, definiert das Protokoll , wie der Zugriff auf das Dokument. Mit anderen Worten, zu welchem Zeitpunkt versucht der Client , um das Dokument zu erhalten, ist er gezwungen , den Server zu sagen , wie es (Server) auf die Handlung gezwungen ist , er (der Client) zu übertragen. Es gibt viele verschiedene Protokolle der Datenübertragung im Netzwerk, einschließlich der am häufigsten HTTP (Hypertext Transfer Protocol - Hypertext Transfer Protocol), FTP (File Transfer Protocol - File Transfer Protocol), mailto (Präfix - Mail - Protokoll - Suite), Datei (Dateizugriffsprotokolle oder Ordner). Protokolltyp definiert das Programm, das die Daten im Protokollformat verarbeiten wird. Da Internet Explorer kann mit Protokolle http, Datei- und ftp arbeiten, aber es kann mit dem mailto - Protokoll nicht. Deshalb, wenn Sie in Ihrem Browser eingeben, in der Adressleiste mailto: microsoft.com, führen Sie dann eine speziell gestaltete E-Mail - Programm , das mit dem Protokoll arbeiten können (zum Beispiel Outlook Express oder The Bat!). Der Protokollname zeigt die wichtigsten in der URL auch durch einen Doppelpunkt gefolgt werden muss. Registrieren Wert spielt keine Rolle.
Unter den Protokollen ziemlich bizarr gefunden wie res Protokoll oder über (für Zinsen können in der Adressleiste des Browsers eingeben diese Adresse zu: <a href="mailto:[email protected]"> Grüße Bill senden </a> auch sehen , was das sein wird ,  . Eine weitere unterhaltsame LDAP - Protokoll (versuchen Sie zum Beispiel ldap: //microsoft.com).
. Eine weitere unterhaltsame LDAP - Protokoll (versuchen Sie zum Beispiel ldap: //microsoft.com).
Als Protokoll für die URL alle Protokolle nicht wirken können. So Berichte über oder Javascript keine Beziehung hat auch das Dokument an die Füllung der Strecke, weil "die Adresse" mit diesen Protokollen sind durch keine URL.
Protokoll-Präfix zeigt dem Kunden auf das, was "Sprache" Kommunikation mit dem Server fließen. Und der Kunde weiß im Voraus, was das Programm diese Kommunikation halten sollte, die nicht über den Server gesagt werden. Um den Server zu sein begann, mit uns zu "sprechen" auf die gewünschte Protokollsprache, er (der Server) hat ein entsprechendes Programm zu laufen, die dieses Protokoll verstehen. Um dieses Problem zu lösen, verwenden Sie Ports. Also , wenn der DNS - Name oder die IP - Adresse des Rechners bestimmt wird , auf die wir verweisen, bestimmt der Port das Programm , auf das wir auf einem bestimmten Host machen. Ports ganze Zahl von 0 bis 65.535 reichen bezeichnet.
Jedes Protokoll wird den Standard-Port zugeordnet, auf dem das Serverprogramm für Client-Anfragen warten. Zum Beispiel, wenn der Server das HTTP - Protokoll unterstützt, wird der entsprechende Server - Software (zB Apache) erwarten Client - Anfragen auf Port 80 (der Standard - Port des Protokolls http empfangen). Wenn diese bla bla Host neben FTP - Protokoll unterstützt, dann der andere Server - Programm lauscht auf Port 21 (der Port für den FTP - Protokoll reserviert).
Hafen auf die wir verweisen wird automatisch ermittelt, je nachdem, welche Protokoll wir in der URL ausgewählt haben. Aber der Hafen auch explizit angeben, erlaubt. Die Portnummer wird durch den Darm nach dem DNS-Namen oder die IP-Adresse angegeben:
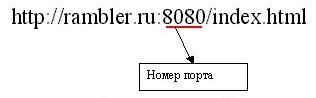
In diesem Beispiel wenden wir uns an einem bestimmten Programm "hängen" auf Port 8080, auch behauptet , dass sie uns die Datei index.html über das HTTP - Protokoll zu geben hat. Wenn srevere ein solches Programm nicht (dann essen Anfragen an Port 8080 kein Programm in irgendeiner Weise nicht aufgespürt werden) angezeigt wird , gibt der Browser uns eine Mitteilung über die falsche URL.
Da der Standard - HTTP - Server - Port 80 angenommen wird, das entspricht die Adresse http://rambler.ru:80 bei http://rambler.ru. Obwohl im Prinzip sind die Gastgeber nicht erforderlich , um es in den HTTP - Port 80 th zu halten. Der Server kann zum Beispiel auf Port 3128, auch zu der Zeit mit dem Host unter http unaufhörliche Notwendigkeit, explizit die Portnummer angeben , zu kommunizieren konfiguriert werden: http://rambler.ru:3128
Wenn der Server manchmal Zugriff es geschieht es notwendig, zusätzlich zu spezifizieren ist Adressen an denselben Benutzer idntifikator zu handeln, die auf den Server zugreift (oder auf die wir den Server einschalten), aber ähnlich wie ein Passwort. URL können Sie diese Informationen zu vermitteln. Um dies zu tun, bevor der DNS - Namen vor dem @ -Zeichen gesetzt wird , die den Benutzernamen angibt:
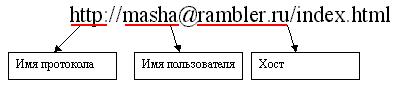
In der Regel wird für HTTP - Protokoll nicht die Benutzerauthentifizierung, aber für Protokolle wie FTP oder mailto sie erforderlich erfordern. Neben dem Benutzernamen, geben Sie die zulässigen und Zugangspasswort. Passwort ist nicht mehr im Namen des Dickdarms. Zum Beispiel: ftp: // Masha: [email protected]. Diese URL - Adresse Anfragen per FTP - Stammverzeichnis des Host - yahoo.com für den Benutzer masha Passwort Kascha. Aber diese Adresse mailto: //[email protected] verwendet , um die Mailbox des Benutzers zuzugreifen im Host masha mail.ru.
Name polzovaetlya ähnlich existieren auf dem Domain-Prinzip aufgebaut, auch aus verschiedenen Elementen zusammengesetzt sein, die durch einen Punkt getrennt. Zum Beispiel mailto: //[email protected].
Wie bereits erwähnt, URL ist der vollständige Pfad des Dokuments. Nach dem Gesetz ist jede Datei, die als Text (zB HTML oder PDF oder DOC-Dateien) und Bild (jpg oder gif), und das Programm existieren kann. Dies bedeutet , dass das http - Protokoll , wenn in der URL - Text angefordert, oder ein Bild, dann müssen sie an den Anwender , um befördert werden , um sie in ihrem Browser angezeigt werden , aber wenn das angeforderte Programm oder Skript, dann muss es auf dem Server ausgeführt werden, und der Benutzer das Ergebnis ihrer Arbeit schicken. Selbst das Ergebnis kann entweder Text oder ein Bild sein. Geben Sie rezultirueschego Handlung im Programm selbst definiert, und der Benutzer nicht weiß im Voraus, welche Art von Dokument es empfängt, so dass das Programm. Rufen Sie den Server-Programm über die normale URL-Adresse des Programms oder Skripts. Typischerweise wird in einem Netzwerk - Skripte mit der Endung .pl mit .cgi .php (die ersten beiden repräsentieren Programme geschrieben in Perl und PHP, jedoch kann die letzte Erweiterung für alle ausführbaren Dateien angewendet werden, einschließlich auch für Perl und PHP auch EXE). Zum Beispiel wird URL http://www.rambler.ru/cgi-bin/top.cgi Adresse erforderlich auf dem Host rambler.ru bestimmte Anwendung top.cgi laufen übertragen dem Kunden auch das Ergebnis der Arbeit dieser Anwendung (zB HTML - Dokument oder Bild).
Aber von den Server-Anwendungen sind ein wenig verwirrt gewesen, wenn sie Parameter nicht möglich war, zu übergeben. URL erlaubt es. So übergeben Parameter auf serverbasierte Anwendungen (auch als Gateways) ein Datenformat unter Verwendung bekannter als CGI (Common Gateway Interface). Dieses Format ermöglicht das Programm die Eingabedaten in einer einzigen Zeile zu setzen.

In diesem Beispiel wird gezeigt , dass eine URL ein Gateway - Server auch genannt wird , überträgt die search.pl als Eingabe ein Parameter namens Benutzer auch zanacheniem Mascha. CGI - String verschwindet aus dem Skriptnamen Zeichen Problem? . Wenn das Skript notwendig ist , mehrere Parameter zu übergeben, werden sie aufgelistet sequentiell durch ein kaufmännisches &, zum Beispiel: http://rambler.ru/cgi-bin/perl/search.pl?user=masha&password=kasha.
Beachten Sie Folgendes: da die meisten der Web-Technologien auf Basis von Textdatenformate, die hell und früh oder später gibt es ein Problem zwischen Code und Daten unterscheiden. Beispiel : = wenn als CGI - Parameter, wollen wir einen Parameter Ausdruck mit einem Wert von C passieren A + B: http://site.com/script.cgi?expression=C=A+B eine solche Anforderung wird als eine andere CGI mißverstanden werden = Zeichen wird als Trennzeichen zwischen dem Parameternamen und seinen Wert wahrgenommen werden. Daher verwendet das CGI - Protokoll (wie auch in Innen URL) eine spezielle Zeichencodierung Datenformat URL aufgerufen.
Diese Codierung zeigt die Buchstaben des Alphabets , wie sie sind, und den Rest der Zeichen in der Form% nn wobei nn - hexadezimale Zeichencode. Zum Beispiel "das doppelte Anführungszeichen wird wie 22% aus, aber als Symbol =% 3D Ausnahme ist das Leerzeichen, die zusätzlich zu den Standard - Codierung
HTTP-Protokoll
HTTP (Hypertext Transfer Protocol) - das Hauptprotokoll im Web verwendet. Obwohl das Protokoll das Hypertext Transfer Protocol (d.h. HTML) genannt wird, kann die Sitzung auf HTTP-Protokoll verwendet werden (und wird), um Daten von praktisch jedem Netzwerk übertragen werden. Es übertragen auch Texte und Bilder als Dateien. HTTP Popularität, meiner Meinung nach, ist auf mehrere Faktoren zurückzuführen: es vielseitig genug ist, URL-Adressierung zu verwenden, die Fähigkeit, alle Daten (wie zum Beispiel dem Server des Kunden sowie umgekehrt) zu übertragen, aber eine ähnliche Arbeit in der No-Line-Modus (dh predachi Daten direkt zwischen Kunden und Server, ohne Vermittler). HTTP-Protokoll genannt dual in dem Sinne erlaubt, dass das Client-Server-System, Daten in den Richtungen des Paares bewegen kann, auch von dem Kunden an den Server von innen nach außen und von dem Server an den Client. Noch persönlich HTTP Syntax wird bei der Datenübertragung von dem Kunden an den Server gerichtet.
So sehen Sie nur eine kleine Auswahl der HTTP-Anforderung. Wenn der Browser - Adressfenster wir die Adresse http://yandex.ru eingeben, wird der Browser die IP - Adresse des Servers identifizieren auch yandex.ru seinen Port 80 eine HTTP - Anforderung senden:
GET http://yandex.ru/ HTTP / 1.0
Akzeptieren: image / gif, image / x-xbitmap, image / jpeg, image / pjpeg, application / vnd.ms-excel, application / msword, application / vnd.ms-Powerpoint, * / *
Accept-Language: ru
Cookie: yandexuid = 2464977781018373381
User-Agent: Mozilla / 4.0 ( compatible; MSIE 5.5; Windows - 98)
Host: yandex.ru
Referer: narod.ru
Proxy-Verbindung: Keep-Alive
Der Antrag wird in Klartext gesendet. Die erste Abfrage ist der Anteil in der ersten Zeile: Dies ist die Art der Anfrage (GET), URL - Adresse des angeforderten Dokuments (http://yandex.ru) als eine Art von HTTP - Protokoll (HTTP / 1.0). Weitere Listen werden die Parameter der Anfrage. Jede Zeile entspricht einem Parameter. An der Quelle der Zeile bewegt den Parameternamen durch einen Doppelpunkt und Parameterwert gefolgt. Die Bedeutung der Parameterspeicher ist intuitiv, aber wir beschreiben die wichtigsten sind: Nehmen Sie - die Art der Daten, die den Browser (codierte MIME) zu nehmen. Accept-Language - die bevorzugte Sprache des Browsers , die Daten empfangen will. User-Agent - eine Art Programm, das die Anforderung gesendet hat . Host - DNS (oder IP) Host - Namen , an die der Antrag gerichtet ist. Cookie - Cookies (Daten , die auf dem Server gespeichert wurde, die Client-lokalen Laufwerk, besuchen Sie den Host letzten Mal). Referer - Host mit kotorgo Seiten verweisen wir die Anfrage. So zum Beispiel , wenn wir auf http://narod.ru Seite sind , und klicken Sie dort http://yandex.ru Link, dann wird die Anfrage an den Host yandex.ru gesendet werden, aber die Referer Anforderungsfeld den Namen des Host - narod.ru haben.
Eine Reihe von Abfrageparametern ist nicht festgelegt. Zusätzlich zu dem Vorstehenden können auch vorhanden andere Optionen.
Der interessanteste Parameterspeicher wie die Referer und Plätzchen. Diese Einstellungen werden in erster Linie für die Benutzerauthentifizierung Server verwendet.
GET-Anforderung können die Daten vom Kunden-Server übertragen haben. Sie sind für die CGI-Protokoll direkt über die URL gesendet. Zum Beispiel in den Chat-Server einzugeben, kann Ihr Browser eine nachfolgende Anforderung senden:
GET http://chat.ru/? Anmeldung = Algol & geben = Algol HTTP / 1.0
Akzeptieren: image / gif, image / x-xbitmap, image / jpeg, image / pjpeg, application / vnd.ms-excel, application / msword, application / vnd.ms-Powerpoint, * / *
Accept-Language: ru
Cookie: yandexuid = 2464977781018373381
User-Agent: Mozilla / 4.0 ( compatible; MSIE 5.5; Windows - 98)
Host: yandex.ru
Referer: narod.ru
Proxy-Verbindung: Keep-Alive
Kaka wir die Query-String enthält Login und Passwort des Benutzers sehen, gesendeten Nachrichten über die URL-String. Solche Servertyp eine Datenübertragung ist bequem, aber hat Kapazitätsbeschränkungen. Äußerst beeindruckend Datenmengen können nicht über die URL übertragen. Für diese Zwecke gibt es eine andere Art von zprosov: POST - Anforderung. Anfrage POST sehr ähnlich dem GET, mit dem einzigen Unterschied , dass nur Daten POST - Anfrage getrennt von der eigentlichen Request - Header übertragen wird. Da die Probe in einer POST - Form hat die Form oben:
POST http://chat.ru/ HTTP / 1.0
Akzeptieren: image / gif, image / x-xbitmap, image / jpeg, image / pjpeg, application / vnd.ms-excel, application / msword, application / vnd.ms-Powerpoint, * / *
Accept-Language: ru
Cookie: yandexuid = 2464977781018373381
User-Agent: Mozilla / 4.0 ( compatible; MSIE 5.5; Windows - 98)
Host: yandex.ru
Referer: narod.ru
Proxy-Verbindung: Keep-Alive
login = Algol & pass = Algol
Da wir die Daten über die Login und Passwort beobachten sind separat in den Körper der Anforderung übertragen. Anfrage Körper sollte aus dem Header leeren String fallen weg. Wenn der Server eine leere Zeile in einer POST - Anforderung trifft, dann werden alle weiteren Schritte er hält den Antrag Körper (tragenen Daten). Beachten Sie folgendes: danyh Format im Körper des POST - Anforderung beliebig. Trotz der Tatsache, dass am häufigsten CGI-Format verwendet, ist es nicht erforderlich. Neben POST - Anfrage benötigt keine Abfrage Körper auch Daten über ähnliche URL übertragen kann.
Zusätzlich zu CGI-Format, manchmal für eine beeindruckende Menge von Informationen zu übertragen (beispielsweise Dateien) verwendet die sogenannte mehrteiliger Format:
POST http://photo.bigmir.net/form.php HTTP / 1.0
Akzeptieren: image / gif, image / x-xbitmap, image / jpeg, image / pjpeg, application / vnd.ms-excel, application / msword, application / vnd.ms-Powerpoint, * / *
Referer: http://photo.bigmir.net/form.php
Accept-Language: ru
Content-Type: multipart / form- Daten; boundary = --------------------------- 7d20345dc
Accept-Encoding: gzip, deflate
User-Agent: Mozilla / 4.0 ( compatible; MSIE 5.01; Windows - 98)
Host: photo.bigmir.net
Proxy-Verbindung: Keep-Alive
Pragma: no-cache
Cookie: Ukrainisch = 2;
BSX_TestCookie = Ja;
rich_ad = 1;
b = 1
----------------------------- 7d20345dc
Content-Disposition: form-data;
name = "id"
254353
----------------------------- 7d20345dc
Content-Disposition: form-data;
name = "d"
22
----------------------------- 7d20345dc
Content-Disposition: form-data;
name = "login"
Algol
----------------------------- 7d20345dc
Content-Disposition: form-data;
name = "passw"
Algol
----------------------------- 7d20345dc
Content-Disposition: form-data;
name = "E - Mail"
[email protected]
----------------------------- 7d20345dc
Content-Disposition: form-data;
name = "submit"
hinzufügen
----------------------------- 7d20345dc--
Lassen Sie uns Sorge auf die Titelleiste des Content-Type: multipart / form- Daten; boundary = --------------------------- 7d20345dc. Dieser Parameter drückt den Server, der Client --------------------------- 7d20345dc die Daten in dem Format mehrteiliger c Begrenzer sendet. Der Begrenzer wird zufällig generiert durch den Kunden auch in der Anfrage Körper geschickt, dass serevere der Lage, um sicherzustellen, erforderlich sein, um die verschiedenen Elemente zu trennen. Wie Sie sehen können, der Körper eine Anzahl von Elementen enthält , die im ASCII - Format (aber nicht in Unicode als für CGI erforderlich) übertragen werden , teilte auch , dass eine Zeichenfolge , die in dem Parameterspeicher Content-Type angegeben wurde. Jeder Lappen enthält Informationen über die Art der übertragenen Daten und der Name dieses Teils. Comfort Multipart - Format ist , dass die übertragenen Daten auch unbegrenzt Wert nicht über Pre-Codierung erfordern.
Zusätzlich Anfragen GET und POST, gibt es auch andere, wie TRACE, PUT. Aber sie sind nur selten genutzt, und wir werden auf sie nicht wohnen.
An einem anderen Tag werde ich die Pflege der Tatsache verschließen, dass alle Informationen an den Client-Server übertragen wird, im Titel und Körper des Antrags enthalten. Eine andere Möglichkeit kann der Server keine Informationen vom Client über HTTP zu bekommen.
Auf der anderen Seite und dem Server kann iformatsii nur Einwände gegen die Aufforderung an den Kunden übertragen. Jeder Austausch danymi im HTTP - Protokoll initiiert wird nur durch den Kunden, kann der Server nichts passieren " , nur weil" , sondern nur auf Anfrage.
Wenn wir also die Möglichkeit, zu kontrollieren, ob das übertragene Anfrage besitzen, vollständig wir kontrolliruem vom Server und Client-Informationen erhalten haben. Dies ist nützlich für die Modifikation der übertragenen / angeforderten Daten nicht die Dateien von HTML-Seiten ändern müssen, izmenenyat, Kekse und so weiter, aber nur genug Änderungen in der HTTP-Anforderung zu machen und es an den Server senden. Aber das ist eine andere Chronik ...



Kommentare
im Auge kommentierte halten , dass der Inhalt und der Ton Ihrer Nachrichten , die Gefühle von echten Menschen verletzen können, Respekt und Toleranz gegenüber seinen Gesprächspartnern, auch wenn Sie Ihr Verhalten in Bezug auf die Meinungsfreiheit und die Anonymität des Internets, ändert ihre Meinung nicht teilen, nicht nur virtuell, sondern realen Welt. Alle Kommentare werden aus dem Index, Spam - Kontrolle versteckt.